Hướng dẫn phân tích backlink đối thủ với Python
Phân tích backlink bằng Python script để tìm ra sự khác biệt về khả năng hiển thị giữa bạn và đối thủ cạnh tranh.
Trước đây, chắc hẳn bạn đã nghe đến cách sử dụng dữ liệu từ Ahrefs để phân tích backlink. Trong bài viết này, SEO PLUS sẽ giúp bạn tìm hiểu cách phân tích backlink của đối thủ cạnh tranh bằng cách sử dụng cùng một nguồn dữ liệu Ahrefs để so sánh. Như bạn đã biết, giá trị của các backlink của một trang web đối với SEO nằm ở chất lượng và số lượng. Chất lượng là thẩm quyền của miền (tương đương với xếp hạng miền tương đương của Ahrefs) và số lượng là số lượng miền được đề cập đến.
Thông thường, người ta đánh giá chất lượng của liên kết với data có sẵn trước khi thực hiện đánh giá số lượng.
import re
import time
import random
import pandas as pd
import numpy as np
import datetime
from datetime import timedelta
from plotnine import *
import matplotlib.pyplot as plt
from pandas.api.types import is_string_dtype
from pandas.api.types import is_numeric_dtype
import uritools
pd.set_option('display.max_colwidth', None)
%matplotlib inline
root_domain = 'johnsankey.co.uk'
hostdomain = 'www.johnsankey.co.uk'
hostname = 'johnsankey'
full_domain = 'https://www.johnsankey.co.uk'
target_name = 'John Sankey'
Nội dung chính
Nhập và Làm sạch Dữ liệu
Các chuyên gia SEO thường thiết lập các tệp thư mục để có thể đọc được nhanh hơn, ít nhàm chán hơn và hiệu quả hơn với nhiều tệp dữ liệu xuất Ahrefs trong cùng một thư mục, so với đọc từng tệp riêng lẻ.
Đặc biệt là khi bạn có tới hơn 10 tệp trong số đó!
ahrefs_path = 'data /'
Hàm listdir () từ mô-đun OS cho phép chúng ta liệt kê tất cả các tệp trong một thư mục con.
ahrefs_filenames = os.listdir(ahrefs_path)
ahrefs_filenames.remove('.DS_Store')
ahrefs_filenames
File names now listed below:
['www.davidsonlondon.com--refdomains-subdomain__2022-03-13_23-37-29.csv',
'www.touchedinteriors.co.uk--refdomains-subdo__2022-03-13_23-42-05.csv',
'www.stephenclasper.co.uk--refdomains-subdoma__2022-03-13_23-47-28.csv',
'www.lushinteriors.co--refdomains-subdomains__2022-03-13_23-44-34.csv',
'www.kassavello.com--refdomains-subdomains__2022-03-13_23-43-19.csv',
'www.tulipinterior.co.uk--refdomains-subdomai__2022-03-13_23-41-04.csv',
'www.tgosling.com--refdomains-subdomains__2022-03-13_23-38-44.csv',
'www.onlybespoke.com--refdomains-subdomains__2022-03-13_23-45-28.csv',
'www.williamgarvey.co.uk--refdomains-subdomai__2022-03-13_23-43-45.csv',
'www.hadleyrose.co.uk--refdomains-subdomains__2022-03-13_23-39-31.csv',
'www.davidlinley.com--refdomains-subdomains__2022-03-13_23-40-25.csv',
'johnsankey.co.uk-refdomains-subdomains__2022-03-18_15-15-47.csv']
Với các tệp được liệt kê, chúng ta có thể đọc từng tệp riêng lẻ bằng vòng lặp for và thêm chúng vào khung dữ liệu.
Trong khi đọc trong tệp, hãy sử dụng một số thao tác chuỗi để tạo một cột mới với tên trang web của dữ liệu mà bạn đang nhập.
ahrefs_df_lst = list()
ahrefs_colnames = list()
for filename in ahrefs_filenames:
df = pd.read_csv(ahrefs_path + filename)
df['site'] = filename
df['site'] = df['site'].str.replace('www.', '', regex = False)
df['site'] = df['site'].str.replace('.csv', '', regex = False)
df['site'] = df['site'].str.replace('-.+', '', regex = True)
ahrefs_colnames.append(df.columns)
ahrefs_df_lst.append(df)
ahrefs_df_raw = pd.concat(ahrefs_df_lst)
ahrefs_df_raw
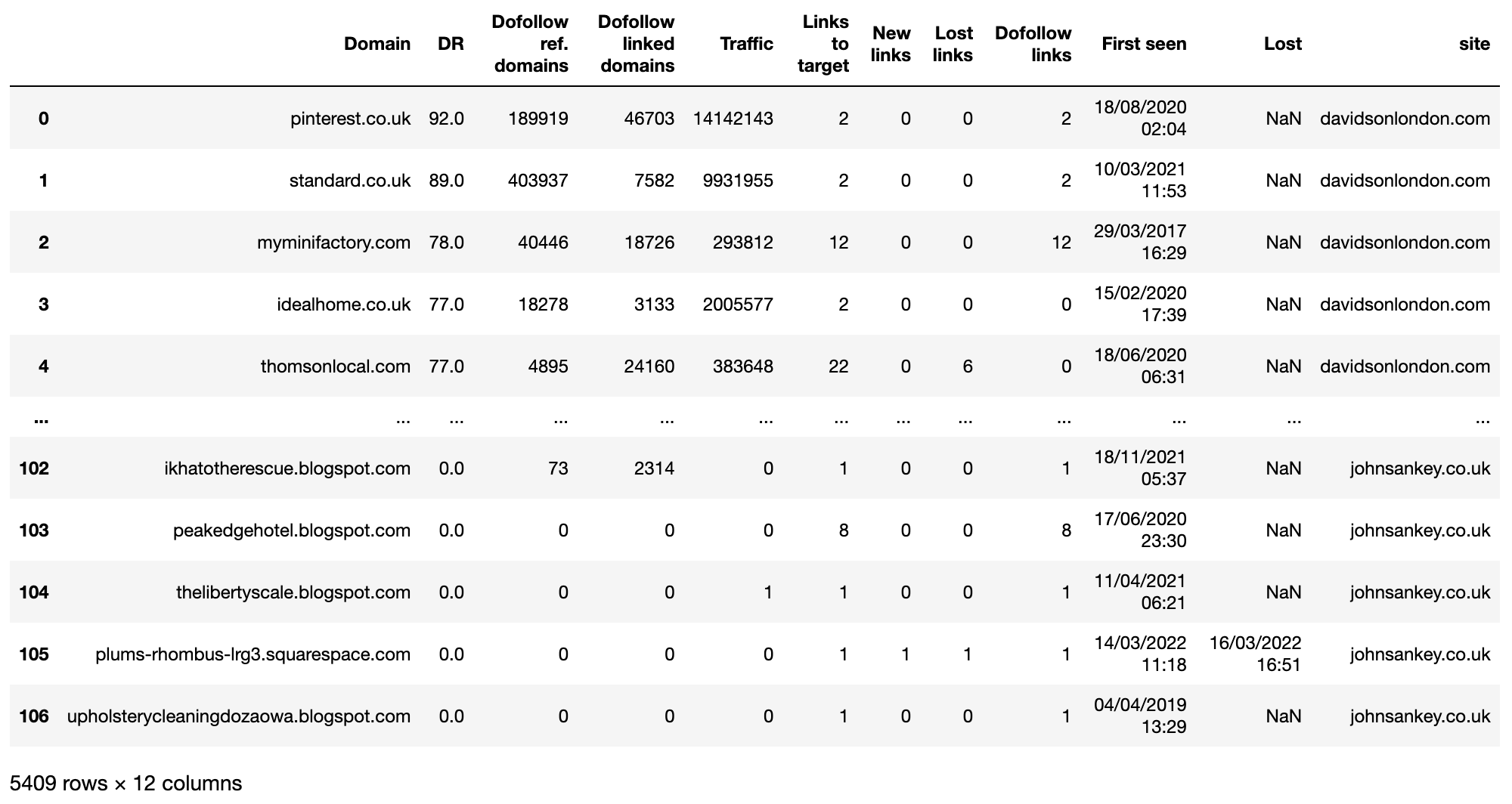
Bây giờ chúng ta đã có dữ liệu thô từ mỗi trang web trong một khung dữ liệu duy nhất. Bước tiếp theo là hãy sắp xếp các tên cột để thuận tiện hơn khi thao tác.
Mặc dù vòng lặp này có thể được loại bỏ bằng một chức năng tùy chỉnh hoặc khả năng đọc hiểu danh sách, thế nhưng việc lặp đi lặp lại chính là một phương pháp hay và dễ dàng hơn cho những Pythonistas mới bắt đầu làm SEO để có thể xem xét kỹ lưỡng từng bước. Việc thực hành lặp đi lặp lại như vậy chắc chắn sẽ giúp bạn thành thạo!
competitor_ahrefs_cleancols = ahrefs_df_raw
competitor_ahrefs_cleancols.columns = [col.lower() for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace(' ','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('.','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('__','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('(','') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace(')','') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('%','') for col in competitor_ahrefs_cleancols.columns]
Sở hữu một cột đếm và một cột giá trị duy nhất (‘project’) rất hữu ích cho các hoạt động phân nhóm và tổng hợp.
competitor_ahrefs_cleancols['rd_count'] = 1
competitor_ahrefs_cleancols['project'] = target_name
competitor_ahrefs_cleancols

Sau khi xử lý và dọn dẹp xong dữ liệu cột, bạn hãy chuyển đến các dữ liệu hàng ngang.
competitor_ahrefs_clean_dtypes = competitor_ahrefs_cleancols
Đối với các referring domain, chúng ta sẽ thay thế dấu gạch ngang bằng số 0 và đặt kiểu dữ liệu là số nguyên, áp dụng lặp lại cho các miền được liên kết.
competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] = np.where(competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] == '-',
0, competitor_ahrefs_clean_dtypes['dofollow_ref_domains'])
competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] = competitor_ahrefs_clean_dtypes['dofollow_ref_domains'].astype(int)
# linked_domains
competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] = np.where(competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] == '-',
0, competitor_ahrefs_clean_dtypes['dofollow_linked_domains'])
competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] = competitor_ahrefs_clean_dtypes['dofollow_linked_domains'].astype(int)
Đầu tiên, bạn sẽ nhìn thấy một điểm mà tại đó các liên kết được tìm thấy, từ đó có thể sử dụng điểm này để lập biểu đồ chuỗi thời gian và xác định số tuổi của đường link. Bạn có thể chuyển đổi sang định dạng ngày tháng bằng cách sử dụng hàm to_datetime.
# first_seen
competitor_ahrefs_clean_dtypes['first_seen'] = pd.to_datetime(competitor_ahrefs_clean_dtypes['first_seen'],
format='%d/%m/%Y %H:%M')
competitor_ahrefs_clean_dtypes['first_seen'] = competitor_ahrefs_clean_dtypes['first_seen'].dt.normalize()
competitor_ahrefs_clean_dtypes['month_year'] = competitor_ahrefs_clean_dtypes['first_seen'].dt.to_period('M')
Để tính tuổi của link, bạn chỉ cần lấy ngày hôm nay trừ đi ngày được nhìn thấy đầu tiên và biến sự khác biệt đó thành một con số.
# link age
competitor_ahrefs_clean_dtypes['link_age'] = dt.datetime.now() - competitor_ahrefs_clean_dtypes['first_seen']
competitor_ahrefs_clean_dtypes['link_age'] = competitor_ahrefs_clean_dtypes['link_age']
competitor_ahrefs_clean_dtypes['link_age'] = competitor_ahrefs_clean_dtypes['link_age'].astype(int)
competitor_ahrefs_clean_dtypes['link_age'] = (competitor_ahrefs_clean_dtypes['link_age']/(3600 * 24 * 1000000000)).round(0)
Cột mục tiêu sẽ giúp chúng bạn phân biệt web của bạn và web của đối thủ cạnh tranh, rất hữu ích cho vấn đề hình dung sau này.
competitor_ahrefs_clean_dtypes['target'] = np.where(competitor_ahrefs_clean_dtypes['site'].str.contains('johns'),
1, 0)
competitor_ahrefs_clean_dtypes['target'] = competitor_ahrefs_clean_dtypes['target'].astype('category')
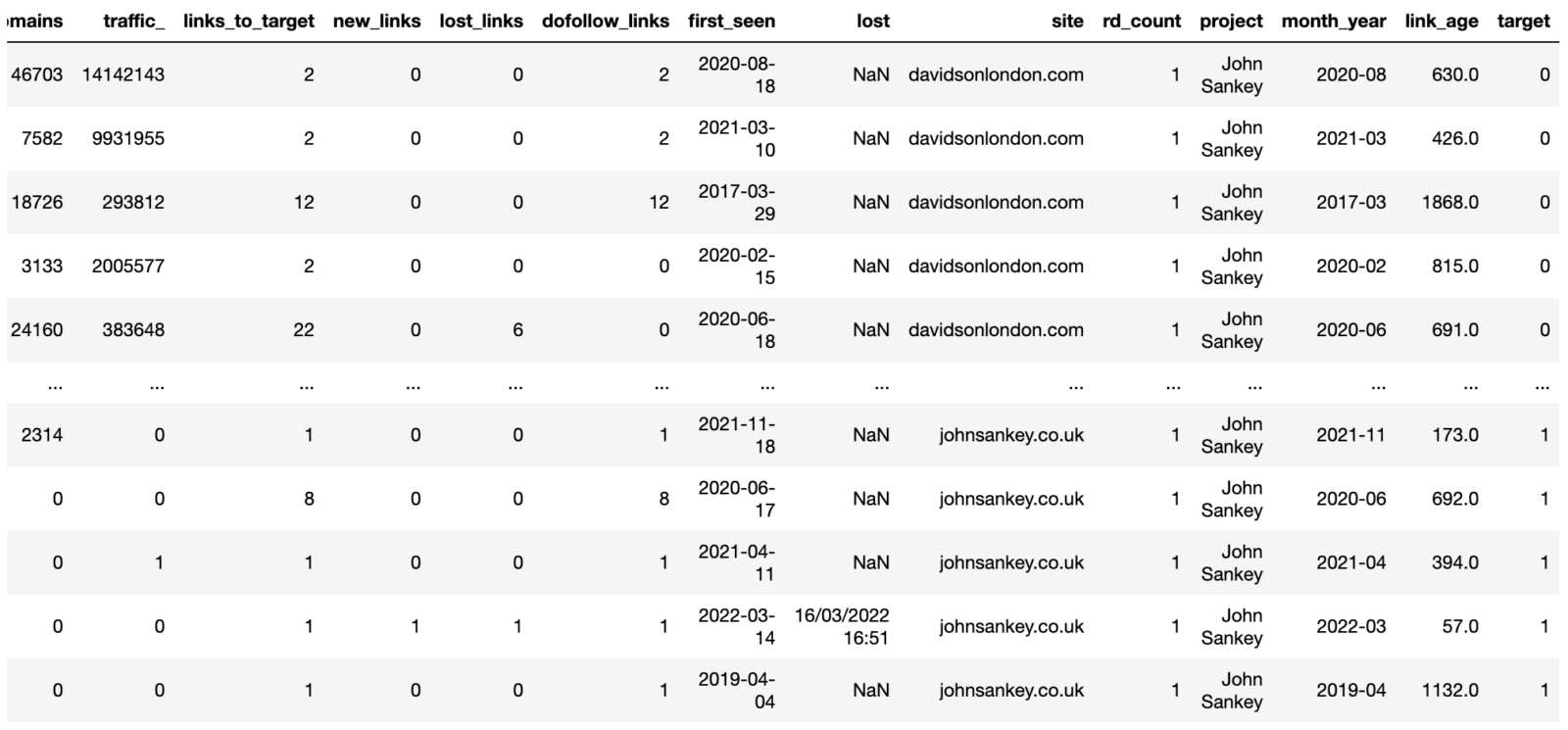
competitor_ahrefs_clean_dtypes
Bây giờ, mọi dữ liệu đã được làm sạch cả về tiêu đề cột và giá trị hàng, cho nên các dữ liệu cũng đã sẵn sàng được thiết lập và bắt đầu phân tích.
Chất lượng liên kết
Khi nhắc đến Chất lượng liên kết (Link Quality), tức là chúng ta sẽ chấp nhận sử dụng Xếp hạng tên miền (Domain Rating – DR) làm thước đo.
Hãy bắt đầu bằng cách kiểm tra các thuộc tính phân phối của DR bằng cách vẽ biểu đồ phân bổ thông qua hàm geom_bokplot.
comp_dr_dist_box_plt = (
ggplot(competitor_ahrefs_analysis.loc[competitor_ahrefs_analysis['dr'] > 0],
aes(x = 'reorder(site, dr)', y = 'dr', colour = 'target')) +
geom_boxplot(alpha = 0.6) +
scale_y_continuous() +
theme(legend_position = 'none',
axis_text_x=element_text(rotation=90, hjust=1)
))
comp_dr_dist_box_plt.save(filename = 'images/4_comp_dr_dist_box_plt.png',
height=5, width=10, units = 'in', dpi=1000)
comp_dr_dist_box_plt
Biểu đồ so sánh các thuộc tính thống kê của trang web thường song song với nhau và đáng chú ý nhất là độ trải giữa sẽ là khu vực mà hầu hết các referring domain đều nằm trong xếp hạng tên miền.
Có thể dễ dàng thấy trong VD rằng John Sankey có xếp hạng tên miền trung bình cao thứ tư với chất lượng liên kết tốt trong tương quan so sánh với các trang web khác. William Garvey có phạm vi DR đa dạng nhất so với các tên miền khác, cho thấy các tiêu chí dễ dàng hơn bao giờ hết cho việc mua lại liên kết.
Link Volumes
Ở trên chúng ta hoàn toàn đề cập đến vấn đề về chất lượng. Vậy còn vấn đề về khối lượng liên kết từ các referring domain thì sao?
Để giải quyết vấn đề số lượng, chúng ta sẽ tính toán tổng số các referring domain đang chạy bằng cách sử dụng hàm groupby.
competitor_count_cumsum_df = competitor_ahrefs_analysis
competitor_count_cumsum_df = competitor_count_cumsum_df.groupby(['site', 'month_year'])['rd_count'].sum().reset_index()
Chức năng mở rộng cho phép cửa sổ tính toán phát triển theo số hàng. Kết quả là một khung dữ liệu với trang web, month_year và count_runsum (tổng đang chạy), ở định dạng hoàn hảo để có thể cung cấp biểu đồ.
competitor_count_cumsum_df['count_runsum'] = competitor_count_cumsum_df['rd_count'].expanding().sum()
competitor_count_cumsum_df
Biểu đồ hiển thị số lượng tên referring domain cho mỗi trang web kể từ năm 2014. Như vậy, mỗi trang web sẽ có các vị trí bắt đầu khác nhau khi bước đầu sở hữu các liên kết.
Ví dụ, William Garvey có thể bắt đầu nghiên cứu hơn 5.000 tên miền. Trong khi đó, Hadley Rose mất 3 năm để bắt đầu mua lại liên kết từ năm 2018 đến 2021.
Tổng kết:
Bạn có thể thử nhiều ứng dụng với phương pháp này. Ví dụ: một phần mở rộng tức thì và tự nhiên ở trên là kết hợp cả chất lượng (DR) và số lượng (khối lượng) để có cái nhìn tổng thể hơn về cách các trang web cạnh tranh về mặt SEO ngoại vi. Các tiện ích mở rộng khác sẽ là mô hình hóa chất lượng của referring domain cho cả trang web của riêng bạn và trang web của đối thủ cạnh tranh để xem các tính năng liên kết nào (chẳng hạn như số lượng từ hoặc mức độ liên quan của nội dung liên kết), từ đó giải thích sự khác biệt về khả năng hiển thị giữa bạn và đối thủ cạnh tranh.
Hi vọng những kiến thức này sẽ giúp bạn phân tích đối thử và đưa ra chiến lược xây dựng backlink hiệu quả hơn.








