Duplicate content là gì? Cách khắc phục để Website lên TOP Google Search
Trong hành trình tối ưu hóa website, Duplicate Content (nội dung trùng lặp) được ví như một “sát thủ thầm lặng” có thể bào mòn sức mạnh xếp hạng và lãng phí ngân sách thu thập dữ liệu (Crawl Budget) của bạn mà không hề báo trước. Tại SEO PLUS, qua kinh nghiệm triển khai hàng trăm dự án thực tế, chúng tôi nhận thấy rằng đây chính là rào cản lớn nhất khiến nhiều website không thể bứt phá lên Top đầu dù đã đầu tư mạnh mẽ vào Onpage.
Bài viết này sẽ giúp bạn bóc tách chi tiết 18 nguyên nhân phổ biến gây trùng lặp nội dung, từ các lỗi kỹ thuật URL phức tạp đến sai lầm trong quản trị nội dung, đồng thời cung cấp quy trình khắc phục triệt để. Hãy cùng SEO PLUS xây dựng một nền tảng Technical SEO vững chắc, độc bản để chinh phục các thuật toán khắt khe nhất của Google và dẫn đầu trong kỷ nguyên tìm kiếm bằng AI.
Nội dung chính
Duplicate Content là gì?
Duplicate Content là tình trạng khi một phần hoặc toàn bộ nội dung giống nhau xuất hiện trên nhiều URL khác nhau, có thể nằm trong cùng một website hoặc giữa nhiều website.
Theo kinh nghiệm triển khai thực tế của SEO PLUS, Duplicate Content được chia thành 2 nhóm chính:
- Internal Duplicate Content: trùng lặp nội dung trong cùng một domain
- External Duplicate Content: trùng lặp giữa các domain khác nhau
Không chỉ dừng ở việc “copy nội dung”, Duplicate Content còn bao gồm:
- URL khác nhau nhưng nội dung giống nhau
- Nội dung gần giống (near duplicate)
- Các phiên bản URL phát sinh từ hệ thống CMS, filter, tracking
Điều quan trọng cần hiểu: Duplicate Content là vấn đề kỹ thuật + cấu trúc + quản trị nội dung, không chỉ là vấn đề copywriting.

Tại sao Duplicate Content có hại cho SEO?
Duplicate Content là một trong những vấn đề kỹ thuật SEO phổ biến nhưng lại có sức tàn phá âm thầm nhất đối với hiệu suất của một website. Dưới đây là phân tích chi tiết về lý do tại sao nó lại gây hại cho chiến lược SEO của bạn:
Sự bối rối của các thuật toán tìm kiếm
Google và các công cụ tìm kiếm khác luôn ưu tiên trải nghiệm người dùng bằng cách cung cấp các kết quả đa dạng và duy nhất. Khi có nhiều trang có nội dung giống hệt hoặc gần như tương tự, thuật toán sẽ gặp khó khăn trong việc:
- Xác định phiên bản gốc: Google không biết trang nào là phiên bản “chính chủ” để ưu tiên hiển thị.
- Hợp nhất các tín hiệu xếp hạng: Thay vì tập trung tất cả sức mạnh (Backlinks, độ uy tín) vào một trang duy nhất, sức mạnh này bị xẻ nhỏ ra cho nhiều URL khác nhau. Điều này gọi là hiện tượng pha loãng Link Equity.
- Lựa chọn URL Canonical: Nếu bạn không chỉ định rõ ràng, Google có thể chọn sai phiên bản để lập chỉ mục, dẫn đến việc trang bạn muốn SEO lại không xuất hiện trên kết quả tìm kiếm.
Lãng phí tài nguyên thu thập dữ liệu (Crawl Budget)
Mỗi website có một “ngân sách thu thập dữ liệu” nhất định. Robot của Google (Googlebot) chỉ dành một khoảng thời gian hữu hạn để quét trang web của bạn.
- Nếu bot phải mất thời gian đi qua hàng chục trang nội dung trùng lặp (ví dụ: các trang lọc sản phẩm, các phiên bản URL có tham số theo dõi), nó có thể bỏ lỡ những trang mới hoặc nội dung quan trọng thực sự cần được index.
- Hệ quả: Nội dung mới cập nhật chậm được xuất hiện trên Google, làm giảm khả năng cạnh tranh.
Hiệu ứng “Tự ăn thịt” từ khóa (Keyword Cannibalization)
Khi bạn có nhiều trang cùng nhắm tới một nhóm từ khóa với nội dung tương tự, các trang này sẽ vô tình trở thành đối thủ của nhau. Thay vì cạnh tranh với các website khác, các URL trên chính web của bạn lại đang “đấu đá” để dành vị trí trên trang kết quả tìm kiếm (SERP). Điều này thường dẫn đến việc không có trang nào đạt được thứ trang cao (Top 1-3).
Ảnh hưởng đến các tính năng hiện đại
Trong kỷ nguyên của SGE (Search Generative Experience) và AI Overview, Google tìm kiếm những nguồn tin có độ tin cậy và tính độc bản (Unique) cao nhất để tổng hợp câu trả lời.
Nội dung sao chép hoặc trùng lặp sẽ bị hệ thống AI loại bỏ ngay từ vòng lọc đầu tiên vì không mang lại giá trị gia tăng (Added Value) so với dữ liệu đã có.

Duplicate Content ảnh hưởng tới SEO web như thế nào?
Duplicate Content không chỉ là một lỗi kỹ thuật đơn thuần mà còn là “kẻ thù” trực tiếp của hiệu suất SEO. Khi một website tồn tại quá nhiều nội dung giống nhau, hệ thống của Google sẽ phải tự đưa ra các quyết định thay vì đi theo lộ trình bạn mong muốn, dẫn đến 4 hệ quả nghiêm trọng sau:
Xuất hiện những URL không mong muốn và kém thân thiện trên kết quả tìm kiếm
Thay vì hiển thị trang đích đã được tối ưu, Google có thể lập chỉ mục (index) sai những phiên bản URL không chuẩn. Điều này thường xảy ra với:
- URL chứa tham số: Các đoạn mã theo dõi chiến dịch (?utm_source=…) hoặc các bộ lọc sản phẩm (?filter=…, ?sort=…).
- Môi trường thử nghiệm: Các trang staging/test chưa được chặn bot.
- URL lỗi cấu trúc: Những đường dẫn chứa ký tự lạ, ID dài loằng ngoằng không chứa từ khóa mục tiêu.
Hệ quả trực tiếp:
- Giảm CTR (Tỷ lệ nhấp): Người dùng thường e ngại các đường dẫn lạ và có xu hướng click vào những URL ngắn gọn, rõ ràng.
- Trải nghiệm người dùng kém: Khách hàng có thể bị điều hướng vào những trang chưa hoàn thiện hoặc trang lọc thay vì trang danh mục chính.
- Độ tin cậy thương hiệu: Sự thiếu nhất quán trong hiển thị URL làm website trở nên thiếu chuyên nghiệp trong mắt người tìm kiếm.

Khiến cho quá trình thu thập thông tin (Crawl) bị chậm lại
Mỗi website đều được Google cấp cho một Crawl Budget (ngân sách thu thập dữ liệu) nhất định. Khi website tồn tại hàng nghìn URL trùng lặp:
- Lãng phí tài nguyên của Bot: Googlebot phải mất thời gian và băng thông để quét những trang không có giá trị mới, thay vì tập trung vào những thay đổi quan trọng.
- Trang quan trọng bị bỏ sót: Các nội dung mới, sản phẩm mới hoặc bài viết vừa cập nhật có thể bị bot “bỏ qua” hoặc crawl rất chậm do ngân sách đã cạn kiệt cho các trang rác.
Vấn đề này trở nên đặc biệt nghiêm trọng với các website thương mại điện tử (có hàng nghìn sản phẩm, thuộc tính) hoặc các trang tin tức có cấu trúc phân loại phức tạp.
Phân tán giá trị liên kết (Link Equity)
Link Equity (hay sức mạnh liên kết) là “dòng máu” giúp website thăng hạng. Khi nội dung bị phân tán ra nhiều URL khác nhau, giá trị này bị chia nhỏ thay vì hội tụ.
- Ví dụ điển hình: Bạn có 3 URL cùng một nội dung: /san-pham, /san-pham?ref=ads, và /san-pham/. Nếu các website khác trỏ backlink về cả 3 URL này, sức mạnh sẽ bị chia làm 3.
- Hệ quả: Không có bất kỳ URL nào tích lũy đủ độ uy tín để cạnh tranh ở những vị trí Top đầu. Thay vì có một trang “siêu mạnh”, bạn lại có nhiều trang “yếu”, khiến tổng thể chiến dịch SEO kém hiệu quả.
Nội dung không được phân phối đúng, ảnh hưởng trực tiếp tới thứ hạng
Trong trường hợp trùng lặp nội dung ngoài website (External Duplicate Content), rủi ro lớn nhất là bạn đánh mất quyền kiểm soát vị trí hiển thị:
- Bị website khác Outrank: Nếu nội dung của bạn bị copy sang một trang web có độ uy tín (Authority) cao hơn, Google có thể ưu tiên hiển thị trang đó và đẩy bài viết gốc của bạn xuống vị trí thấp hơn.
- Không xác định được nguồn gốc: Khi Google không thể phân biệt đâu là nội dung gốc, nó có thể loại bỏ hoàn toàn trang của bạn khỏi kết quả tìm kiếm để tránh hiển thị trùng lặp cho người dùng.
Nguyên nhân phổ biến dẫn đến tình trạng này:
- Nội dung bị đối thủ hoặc các trang spam copy tự động.
- Quên cấu hình thẻ Canonical để khai báo “chủ quyền” cho nội dung gốc.
- Nội dung không được index sớm, tạo điều kiện cho các website khác lập chỉ mục trước và “cướp” mất tính độc bản.
Để tránh những rủi ro này, việc rà soát định kỳ và sử dụng các công cụ kỹ thuật để xử lý Duplicate Content là ưu tiên hàng đầu nếu bạn muốn website tăng trưởng bền vững.
Google có phạt Duplicate Content không?
Google không có “hình phạt” (penalty) chính thức nào dành riêng cho nội dung trùng lặp theo cách mà họ phạt các lỗi như mua bán link hay ẩn text. Tuy nhiên, hệ quả của nó lại gây ra thiệt hại về thứ hạng tương đương, thậm chí nặng nề hơn một hình phạt trực tiếp.
Cơ chế xử lý của Google: Sự sàng lọc thay vì Trừng phạt
Thay vì “giam giữ” website của bạn, Google thực hiện một quy trình lọc để đảm bảo trải nghiệm người dùng tốt nhất:
- Chọn phiên bản Canonical: Google sẽ cố gắng xác định trang nào là trang gốc dựa trên các tín hiệu (như thời gian đăng, cấu trúc link, thẻ canonical).
- Ẩn các phiên bản còn lại: Để tránh việc một kết quả tìm kiếm chỉ toàn những trang giống hệt nhau, Google sẽ “gộp” các trang trùng lặp lại và chỉ hiển thị phiên bản mà họ cho là tốt nhất.
- Giảm khả năng hiển thị: Các trang không được chọn làm “phiên bản gốc” sẽ gần như biến mất khỏi kết quả tìm kiếm (hoặc nằm ở những trang rất sâu), dẫn đến mất hoàn toàn traffic.
Khi nào Duplicate Content trở thành “Hình phạt thủ công”?
Google chỉ thực sự “ra tay” bằng hình phạt thủ công (Manual Action) khi họ nhận thấy hành vi thao túng cố ý.
- Spam quy mô lớn: Sử dụng các công cụ tự động để copy nội dung từ nhiều nguồn khác nhau (Scraped content) nhằm mục đích chiếm lĩnh từ khóa.
- Nội dung rác (Thin content): Tạo ra hàng loạt trang với nội dung tương tự nhau, chỉ thay đổi tên tỉnh thành hoặc từ khóa (thường thấy ở các kỹ thuật SEO mũ đen cũ).
Nếu bạn rơi vào trường hợp này, website có thể bị xóa khỏi chỉ mục của Google hoàn toàn.
“Hình phạt gián tiếp” – Cơn ác mộng của SEOer
Dù không bị Google gửi thông báo phạt, nhưng website vẫn phải đối mặt với sự sụt giảm hiệu suất nghiêm trọng mà SEO PLUS gọi là “hình phạt ẩn”:
| Yếu tố | Tác động gián tiếp |
| Thứ hạng (Ranking) | Các trang tự cạnh tranh lẫn nhau (Keyword Cannibalization), dẫn đến việc không trang nào lọt được vào Top 5. |
| Độ uy tín (Authority) | Google đánh giá thấp chất lượng tổng thể của website nếu tỷ lệ nội dung trùng lặp quá cao (lỗi Panda). |
| Chỉ mục (Indexing) | Những trang nội dung mới, chất lượng cao bị “xếp hàng” chờ đợi vì Google bận xử lý đống nội dung trùng lặp cũ. |
Nguyên nhân phổ biến dẫn đến Duplicate Content và Cách khắc phục
Dưới đây là nội dung chi tiết cho 18 nguyên nhân gây Duplicate Content và cách khắc phục, được SEO PLUS biên soạn chính xác theo cấu trúc mà bạn mong muốn:
Trùng lặp do bộ lọc và tham số URL (Faceted & Filtered Navigation)
Đây là nguyên nhân phổ biến nhất trên các website TMĐT hoặc tin tức lớn, nơi một sản phẩm có thể xuất hiện dưới nhiều đường dẫn khác nhau do người dùng chọn màu sắc, kích thước hoặc giá.
Vấn đề: Các URL như …/giay-nam?color=black và …/giay-nam?sort=price thực chất chỉ hiển thị một danh sách sản phẩm tương tự nhưng Google coi là các trang khác nhau.
Cách khắc phục:
- Sử dụng thẻ Canonical: Đặt thẻ <link rel=”canonical” href=”URL_GỐC” /> trên tất cả các trang lọc để chỉ định trang danh mục chính là bản gốc.
- Cấu hình tham số trong Search Console: Khai báo cho Google biết các tham số như filter hay sort không làm thay đổi nội dung trang.
- Dùng thẻ Noindex: Với các trang lọc quá sâu, hãy đặt thẻ noindex để chặn Google lập chỉ mục.
Tham số theo dõi chiến dịch (Tracking Parameters)
Khi triển khai các chiến dịch Marketing, các mã theo dõi thường được đính kèm vào URL để đo lường hiệu quả từ các nguồn như Facebook, Email hay Google Ads.
Vấn đề: Các mã như ?utm_source=… hay ?gclid=… tạo ra hàng chục phiên bản URL cho cùng một trang đích, làm phân tán sức mạnh SEO.
Cách khắc phục:
- Sử dụng thẻ Canonical: Luôn trỏ Canonical về URL “sạch” (không chứa mã UTM).
- Cấu hình trong Search Console: Sử dụng công cụ “URL Parameters” để báo cho Google bỏ qua các tham số theo dõi này.
ID phiên làm việc (Session IDs)
Nhiều hệ thống website cũ tự động tạo ra một mã định danh duy nhất cho mỗi khách hàng khi họ truy cập vào trang web để lưu trữ giỏ hàng hoặc lịch sử xem.
Vấn đề: Mỗi người dùng mới sẽ tạo ra một URL có đuôi khác nhau (ví dụ: ?sessionid=123), dẫn đến việc Google index hàng nghìn trang có nội dung giống hệt nhau.
Cách khắc phục:
- Dùng Cookie: Cấu hình lại hệ thống để lưu thông tin phiên người dùng qua Cookie thay vì hiển thị trực tiếp trên URL.
- Sử dụng thẻ Canonical: Hợp nhất các phiên bản Session về URL chuẩn của trang.
Xung đột HTTP/HTTPS và WWW/Non-WWW
Sự thiếu đồng nhất trong việc cấu hình giao thức bảo mật và định dạng tên miền khiến website tồn tại nhiều “cổng” truy cập vào cùng một nội dung.
- Vấn đề: Website có thể truy cập bằng cả 4 phiên bản: http://, https://, http://www và https://www. Google coi đây là 4 website riêng biệt trùng lặp nội dung.
- Cách khắc phục: * Redirect 301: Thiết lập chuyển hướng vĩnh viễn toàn bộ về một phiên bản duy nhất (khuyên dùng https://domain.com).
URL phân biệt chữ hoa và chữ thường (Case Sensitivity)
Hầu hết các máy chủ (đặc biệt là Linux) coi chữ hoa và chữ thường trong URL là các đường dẫn khác nhau hoàn toàn.
Vấn đề: Đường dẫn /Dich-Vu/ và /dich-vu/ sẽ dẫn đến hai trang có nội dung giống nhau nhưng tồn tại song song trên chỉ mục của Google.
Cách khắc phục:
- Chuẩn hóa Lowercase: Cấu hình hệ thống tự động chuyển tất cả URL về chữ thường.
- Redirect 301: Chuyển hướng các phiên bản có chữ hoa về phiên bản chữ thường chuẩn SEO.

Dấu gạch chéo ở cuối URL (Trailing Slashes)
Đây là một lỗi kỹ thuật nhỏ nhưng gây ảnh hưởng lớn đến việc xác định URL gốc của các công cụ tìm kiếm.
- Vấn đề: Google phân biệt /san-pham và /san-pham/ là hai thực thể khác nhau, dẫn đến hiện tượng trùng lặp nội dung trên toàn trang.
- Cách khắc phục: * Đồng nhất Format: Chọn một định dạng chuẩn (có hoặc không có dấu /) và cấu hình server để tự động Redirect bản sai về bản chuẩn.
Phiên bản URL dành cho bản in (Print-friendly Pages)
Để hỗ trợ người dùng in ấn tài liệu dễ dàng, nhiều website tạo ra một phiên bản tối giản chỉ chứa văn bản mà không có khung giao diện.
Vấn đề: Phiên bản /bai-viet/print/ chứa 100% nội dung của bài gốc, khiến Google bối rối không biết nên xếp hạng trang nào.
Cách khắc phục:
- Dùng thẻ Noindex: Ngăn Google lập chỉ mục phiên bản in ấn.
- Sử dụng thẻ Canonical: Trỏ Canonical từ trang in về bài viết chính thức trên web.

Triển khai cùng nội dung trên nhiều website (Cross-domain)
Vấn đề này thường xảy ra khi doanh nghiệp sở hữu nhiều tên miền khác nhau và đăng tải cùng một nội dung để bao phủ thị trường.
Vấn đề: Google sẽ đánh giá thấp (hoặc bỏ qua) các trang đăng sau, thậm chí coi đó là hành vi spam nội dung.
Cách khắc phục:
- Canonical Cross-domain: Đặt thẻ Canonical từ các trang phụ trỏ về website chính (nguồn gốc).
- Rewrite nội dung: Viết lại nội dung độc bản cho từng website để tạo sự khác biệt về giá trị.
URL dành riêng cho thiết bị di động (Mobile URLs)
Trước khi công nghệ Responsive phổ biến, nhiều web sử dụng subdomain riêng cho di động như m.domain.com.
Vấn đề: Bản Mobile và bản Desktop có nội dung giống nhau nhưng tồn tại trên hai URL khác nhau, làm loãng sức mạnh SEO.
Cách khắc phục:
- Sử dụng Responsive Design: Dùng một URL duy nhất cho mọi thiết bị.
- Thẻ Alternate/Canonical: Khai báo mối quan hệ giữa bản mobile và desktop để Google hiểu chúng là một.
Phiên bản AMP (Accelerated Mobile Pages)
AMP giúp trang web tải cực nhanh trên di động nhưng lại tạo ra một phiên bản URL riêng biệt (thường có tiền tố /amp/).
- Vấn đề: Nội dung trên trang AMP và trang gốc hoàn toàn trùng khớp, gây ra lỗi Duplicate Content.
- Cách khắc phục: * Sử dụng thẻ Canonical: Luôn luôn đặt thẻ Canonical trên trang AMP trỏ về phiên bản bài viết chính thức trên Desktop.
Trang Tag và Category Pages (Thẻ và Danh mục)
Hệ thống CMS (như WordPress) thường tự động tạo ra các trang lưu trữ cho thẻ (tag) và danh mục (category).
Vấn đề: Nếu một bài viết gắn quá nhiều Tag, các trang Tag này sẽ hiển thị nội dung trích đoạn giống hệt nhau, tạo ra hàng loạt trang “mỏng” và trùng lặp.
Cách khắc phục:
- Noindex Tag: Chặn index các trang Tag nếu chúng không mang lại traffic.
- Tối ưu Category: Viết nội dung mô tả độc bản cho trang danh mục để làm mới nội dung.
URL hình ảnh đính kèm (Attachment Pages)
Khi tải ảnh lên, một số nền tảng tự động tạo ra một trang riêng chỉ để hiển thị duy nhất tấm ảnh đó kèm tiêu đề.
- Vấn đề: Các trang này không có nội dung hữu ích, gây lãng phí Crawl Budget và làm tăng tỷ lệ nội dung trùng lặp rác trên web.
- Cách khắc phục: * Redirect: Cấu hình chuyển hướng (thường dùng Plugin SEO) để đưa URL hình ảnh đính kèm về thẳng bài viết chứa nó.
Phân trang (Pagination)
Các danh mục sản phẩm hoặc tin tức có hàng trăm trang (Trang 2, Trang 3…) thường sử dụng chung một đoạn mô tả danh mục ở đầu trang.
Vấn đề: Tiêu đề và mô tả của các trang sau giống hệt trang 1, khiến Google đánh giá là trùng lặp.
Cách khắc phục:
- Canonical hợp lý: Trỏ Canonical từ trang 2, 3… về chính nó hoặc về trang “Xem tất cả”.
- Tối ưu UX: Thêm tiền tố “Trang 2 – [Tên danh mục]” vào thẻ tiêu đề.
Trùng lặp mô tả sản phẩm (Product Descriptions)
Điều này xảy ra khi bạn bán các sản phẩm có thuộc tính gần giống nhau hoặc sử dụng mô tả mặc định từ nhà sản xuất.
Vấn đề: Hàng nghìn trang sản phẩm có nội dung giới thiệu giống hệt nhau, khiến không trang nào có thể lên Top.
Cách khắc phục:
- Viết nội dung Unique: Viết lại mô tả cho các sản phẩm chủ lực.
- Thêm Review: Khuyến khích khách hàng đánh giá để tạo ra nội dung mới độc bản cho mỗi trang sản phẩm.
Đa ngôn ngữ và Bản địa hóa (Localization)
Website hoạt động trên nhiều quốc gia nhưng nội dung giữa các phiên bản ngôn ngữ (ví dụ: Tiếng Anh cho Mỹ và Anh) quá giống nhau.
Vấn đề: Google không xác định được phiên bản nào dành cho vùng nào, dẫn đến việc hiển thị sai ngôn ngữ trên kết quả tìm kiếm.
Cách khắc phục:
- Thẻ Hreflang: Sử dụng thẻ rel=”alternate” hreflang=”x” để khai báo ngôn ngữ và khu vực cho Google.
- Bản địa hóa: Chỉnh sửa nội dung theo văn phong và thuật ngữ của từng quốc gia.
Điều hướng trang không đúng cách (Poor Redirects)
Khi nâng cấp website hoặc thay đổi cấu trúc URL mà không có kế hoạch chuyển hướng rõ ràng.
- Vấn đề: Tồn tại nhiều URL cũ và mới cùng dẫn đến một nội dung, hoặc các trang cũ bị xóa nhưng vẫn còn được index.
- Cách khắc phục: * Audit Redirect: Kiểm tra và đảm bảo mọi trang cũ đều được Redirect 301 về đúng trang mới tương ứng.
Trang kết quả tìm kiếm nội bộ (Internal Search Pages)
Nhiều website cho phép Google lập chỉ mục các trang kết quả sinh ra khi người dùng tìm kiếm trên thanh Search của web.
- Vấn đề: Các URL dạng ?s=tu-khoa tạo ra vô số trang rác với nội dung chắp vá từ các bài viết khác.
- Cách khắc phục: * Dùng thẻ Noindex: Luôn chặn index các trang kết quả tìm kiếm nội bộ để bảo vệ chất lượng website.
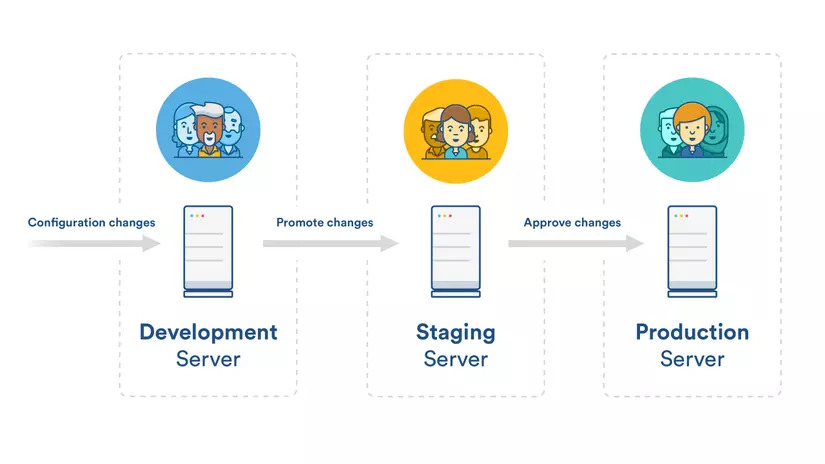
Môi trường Staging/Demo (Development Sites)
Đội ngũ lập trình thường tạo bản web thử nghiệm để test tính năng trước khi đưa vào hoạt động chính thức.
Vấn đề: Nếu không chặn bot, Google sẽ index toàn bộ nội dung của bản thử nghiệm này, gây trùng lặp 100% với bản web thật.
Cách khắc phục:
- Chặn Index: Sử dụng file Robots.txt với lệnh Disallow: / cho bản demo.
- Bảo mật: Thiết lập mật khẩu truy cập (HTTP Authentication) cho môi trường staging.
Cách kiểm tra Duplicate Content trên website
Để website phát triển bền vững, việc chủ động rà soát nội dung trùng lặp là bước không thể thiếu. Dưới đây là hướng dẫn chi tiết các cách kiểm tra Duplicate Content cả nội bộ và bên ngoài, cùng các công cụ hỗ trợ đắc lực nhất hiện nay.
Cách kiểm tra Duplicate Content nội bộ (Internal)
Đây là việc kiểm tra xem các trang trên cùng một website của bạn có đang “giẫm chân” lên nhau hay không.
Sử dụng công cụ Screaming Frog (SEO Spider)
Đây là công cụ mạnh mẽ nhất để quét toàn bộ cấu trúc website và phát hiện các lỗi kỹ thuật.
Cách thực hiện: Nhập URL website vào phần mềm và nhấn Start. Sau khi quét xong, hãy kiểm tra các tab:
- Tab Titles: Lọc các trang có tiêu đề giống nhau (Duplicate).
- Tab Meta Description: Tìm các trang có mô tả trùng lặp.
- Tab Content: Sử dụng tính năng “Near Duplicates” để tìm các trang có nội dung tương đồng trên 90%.
Kiểm tra trực tiếp trên Google Search Console
Google sẽ báo cáo cho bạn những trang mà họ coi là trùng lặp và không lập chỉ mục.
Cách thực hiện: Vào mục Lập chỉ mục (Indexing) -> Trang (Pages). Kiểm tra các trạng thái:
- “Trùng lặp, Google chọn trang chuẩn khác với người dùng”.
- “Trùng lặp, người dùng không chọn trang chuẩn”.
Cách kiểm tra nội dung trùng lặp ngoài trang (External)
Việc này giúp bạn phát hiện xem nội dung của mình có bị đối thủ copy hoặc bạn có vô tình đăng tải nội dung đã tồn tại trên internet hay không.
Kiểm tra bằng phương pháp thủ công (Google Search)
Đây là cách nhanh nhất và hoàn toàn miễn phí để xác minh tính độc bản của một đoạn văn cụ thể.
- Cách thực hiện: Sao chép một đoạn văn bản khoảng 2-3 câu trong bài viết của bạn, đặt vào trong dấu ngoặc kép “[Đoạn nội dung]” và tìm kiếm trên Google.
- Kết quả: Nếu Google trả về nhiều website khác nhau có đoạn văn y hệt, nghĩa là nội dung đã bị trùng lặp bên ngoài.
Kiểm tra thông qua hồ sơ Backlink
Đôi khi, việc một website lạ trỏ rất nhiều link về một bài viết cụ thể của bạn có thể là dấu hiệu họ đã copy bài và quên xóa link nội bộ của bạn.
Cách thực hiện: Sử dụng các công cụ như Ahrefs hoặc Search Console để xem danh sách backlink mới và kiểm tra nguồn gốc của chúng.
Các Tool hỗ trợ Check Duplicate Content Online (Khuyên dùng)
SEO PLUS khuyến nghị bạn nên kết hợp các công cụ sau để có kết quả chính xác nhất:
| Công cụ | Đặc điểm nổi bật | Mục đích sử dụng |
| Copyscape | Công cụ kiểm tra đạo văn “huyền thoại”. | Kiểm tra xem bài viết của bạn có bị web khác copy hay không. |
| Siteliner | Quét toàn bộ website cực nhanh (miễn phí 250 trang). | Phân tích tỉ lệ % trùng lặp nội bộ giữa các trang trong cùng 1 domain. |
| Grammarly | Có tính năng Plagiarism (trả phí). | Kiểm tra tính độc bản ngay trong quá trình soạn thảo nội dung. |
| Ahrefs / SEMrush | Bộ công cụ SEO toàn diện. | Sử dụng tính năng Site Audit để phát hiện lỗi trùng lặp tiêu đề, mô tả và nội dung mỏng toàn trang. |
| Quetext | Sử dụng thuật toán DeepSearch. | Kiểm tra đạo văn chuyên sâu với báo cáo tỷ lệ phần trăm chi tiết. |
Cách xử lý Duplicate Content trên website
Để website vận hành trơn tru và nhận được sự đánh giá cao từ Google, bạn cần có một quy trình xử lý Duplicate Content khoa học. Dưới đây là các bước xử lý chi tiết cho cả nội bộ và bên ngoài trang:
Quy trình xử lý Duplicate Content nội bộ
Đây là việc dọn dẹp các “rác” kỹ thuật trên chính website của bạn để tập trung sức mạnh cho các trang đích quan trọng.
Bước 1: Crawl toàn bộ website Sử dụng các công cụ như Screaming Frog hoặc Siteliner để quét toàn bộ hệ thống URL. Mục tiêu là phát hiện các trang có tiêu đề (Title), mô tả (Meta Description) và nội dung giống nhau trên 90%.
Bước 2: Nhóm các URL trùng lặp Phân loại các URL đang gặp vấn đề theo từng nhóm nguyên nhân (do bộ lọc, do tham số UTM, do trùng lặp nội dung sản phẩm…). Việc nhóm lại giúp bạn đưa ra quyết định xử lý hàng loạt nhanh hơn.
Bước 3: Chọn URL Canonical (Trang chuẩn) Trong một nhóm các trang trùng nhau, bạn phải quyết định đâu là “trang gốc” (trang mang lại giá trị SEO cao nhất). Đây sẽ là trang duy nhất bạn muốn Google xếp hạng.
Bước 4: Thực hiện Redirect hoặc Noindex
- Redirect 301: Dùng khi bạn muốn khai tử các URL phụ và dồn 100% sức mạnh về trang chính.
- Thẻ Canonical: Dùng khi bạn muốn giữ lại các trang phụ cho người dùng trải nghiệm (như trang lọc) nhưng báo Google đừng xếp hạng chúng.
- Thẻ Noindex: Dùng cho các trang rác hệ thống không có giá trị nội dung (trang kết quả tìm kiếm, trang giỏ hàng).
Bước 5: Cập nhật Internal Link (Liên kết nội bộ) Rà soát lại toàn bộ hệ thống link nội bộ trên web. Đảm bảo tất cả các đường dẫn đều trỏ thẳng về URL Canonical, tránh trỏ link vào các URL đã bị Redirect hoặc Noindex.

Cách xử lý tình trạng Duplicate Content ngoài trang
Khi nội dung của bạn bị các website khác sao chép trái phép, hãy áp dụng các biện pháp bảo vệ “chủ quyền” sau:
- Liên hệ trực tiếp yêu cầu gỡ bài Đây là cách văn minh nhất. Hãy tìm thông tin liên hệ (Email, Hotline, Fanpage) của chủ website copy và gửi yêu cầu gỡ bỏ nội dung hoặc yêu cầu họ đặt link nguồn (thẻ Canonical trỏ về bài của bạn).
- Gửi báo cáo vi phạm bản quyền (DMCA) Nếu đối phương không hợp tác, hãy sử dụng Google DMCA Dashboard để gửi yêu cầu gỡ bỏ nội dung vi phạm khỏi kết quả tìm kiếm của Google. Nếu yêu cầu được chấp nhận, trang web copy sẽ bị xóa khỏi Google, thậm chí bị phạt nặng.
- Tăng Authority (Độ uy tín) cho website Google thường ưu tiên xếp hạng cho website có độ uy tín cao hơn. Bằng cách xây dựng Backlink chất lượng và tăng tương tác người dùng, bạn sẽ khẳng định được vị thế “nguồn gốc” của mình, khiến các trang copy không thể vượt mặt (Outrank).
- Thực hiện Index nhanh hơn đối thủ Ngay sau khi xuất bản nội dung, hãy sử dụng công cụ URL Inspection trong Google Search Console để yêu cầu Google lập chỉ mục ngay lập tức. Việc được Index trước giúp bạn xác lập “dấu mốc thời gian” chứng minh mình là tác giả đầu tiên của nội dung đó.
Lời khuyên từ SEO PLUS: “Phòng bệnh hơn chữa bệnh”. Hãy luôn cài đặt mã tự động trỏ Canonical về chính nó (Self-referencing Canonical) cho mọi bài viết ngay từ khi thiết kế website để hạn chế tối đa rủi ro trùng lặp phát sinh trong tương lai.
Dưới đây là phần kết luận tổng kết lại toàn bộ vấn đề về Duplicate Content, giúp bạn xâu chuỗi các kiến thức từ kỹ thuật đến chiến lược nội dung:
Kết luận
Duplicate Content là một trong những vấn đề cốt lõi của Technical SEO nhưng lại thường bị các chủ website xem nhẹ. Việc để mặc cho các URL tự sinh hoặc nội dung bị sao chép không kiểm soát sẽ âm thầm bào mòn sức mạnh của toàn bộ hệ thống SEO mà bạn đã dày công xây dựng.
Lời khuyên chiến lược từ SEO PLUS
Để tối ưu SEO bền vững và tránh các “hình phạt ẩn” từ thuật toán Google, bạn cần thực hiện nghiêm túc 4 trụ cột sau:
- Kiểm soát chặt chẽ cấu trúc URL: Ngay từ khâu thiết kế web, hãy đảm bảo các tham số (filter, UTM, session) được quản lý minh bạch, không tạo ra các “trang rác” cho Googlebot.
- Chuẩn hóa thẻ Canonical: Luôn sử dụng thẻ Canonical như một “chứng minh thư” để xác định chủ quyền cho nội dung gốc, giúp Google không bị bối rối khi lựa chọn trang hiển thị.
- Thực hiện Audit nội dung định kỳ: Sử dụng các công cụ chuyên dụng (Screaming Frog, Siteliner, Search Console) hàng tháng để phát hiện sớm các biến thể nội dung mới phát sinh.
- Kết hợp Kỹ thuật và Chiến lược nội dung: Không chỉ xử lý lỗi code, đội ngũ Content cần tư duy sáng tạo để mỗi trang sản phẩm/dịch vụ đều mang lại giá trị độc bản (Unique) cho người dùng.
Giá trị nhận lại của một website “sạch”
Một website được tối ưu, không có Duplicate Content sẽ mang lại những lợi thế cạnh tranh vượt trội:
- Tối ưu hóa Crawl Budget: Giúp Googlebot tập trung nguồn lực vào những trang quan trọng nhất, giúp nội dung mới được index thần tốc.
- Tăng sức mạnh Ranking: Hợp nhất toàn bộ Link Equity (sức mạnh liên kết) về một mối, tạo đà bứt phá cho các từ khóa khó lên Top đầu.
- Cải thiện khả năng xuất hiện trên AI Overview: Trong kỷ nguyên tìm kiếm bằng AI, chỉ những nội dung độc nhất, có giá trị chuyên sâu mới được ưu tiên trích dẫn làm câu trả lời cho người dùng.
Xử lý Duplicate Content không phải là công việc làm một lần rồi thôi, mà là một hành trình duy trì sự tinh gọn cho website. Đây chính là nền tảng vững chắc để xây dựng một hệ thống SEO mạnh mẽ, bền vững và có khả năng dẫn đầu thị trường trong dài hạn.
Ngoài ra, nếu bạn có nhu cầu sử dụng dịch vụ seo tại Hà Nội vui lòng liên hệ ngay với chúng tôi để được tư vấn hiệu quả nhất, Hotline: 08288 22226